

Introduction
Last semester, I worked on a confidential consultancy project in my MBA cohort under Prof. John Burr’s guidance. Our client wanted to expand operations across the U.S. by investing up to $50 MM in the industrial casting sector, but the sheer volume of firms made manual data gathering impossible. Necessity being the mother of invention, I built a pipeline to pull firm data by NAICS/SIC codes (or keywords) and automate filtering based on custom criteria.
In this post, you’ll see:
- How to grab a full CSV from DataAxle by NAICS, SIC, or keywords
- Why we augment code-based filters with simple web-crawling (to weed out false positives)
- How to layer on AI (using Agno with Perplexity) for thesis-driven “fit” scoring
- A walk-through of the complete Python script that outputs a ready-to-go Excel sheet
Downloading Your Base Dataset from DataAxle
- Log in to your Data Axle account and navigate to the data search interface.
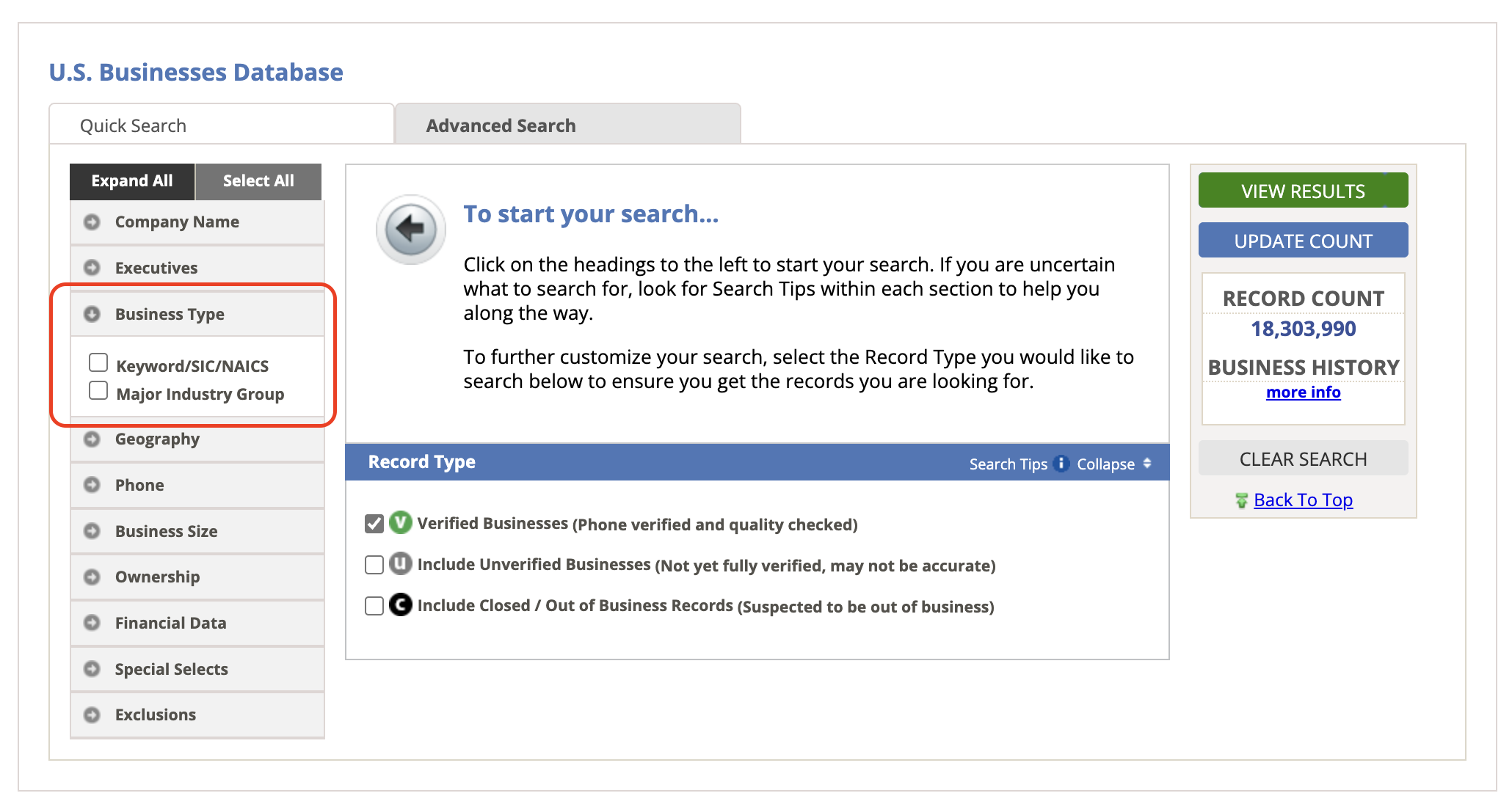
- Use the filtering options to narrow down your dataset:
- Location, industry, and other relevant criteria.
- For an exhaustive list, select Business Type and then Keywords/SIC/NAICS.
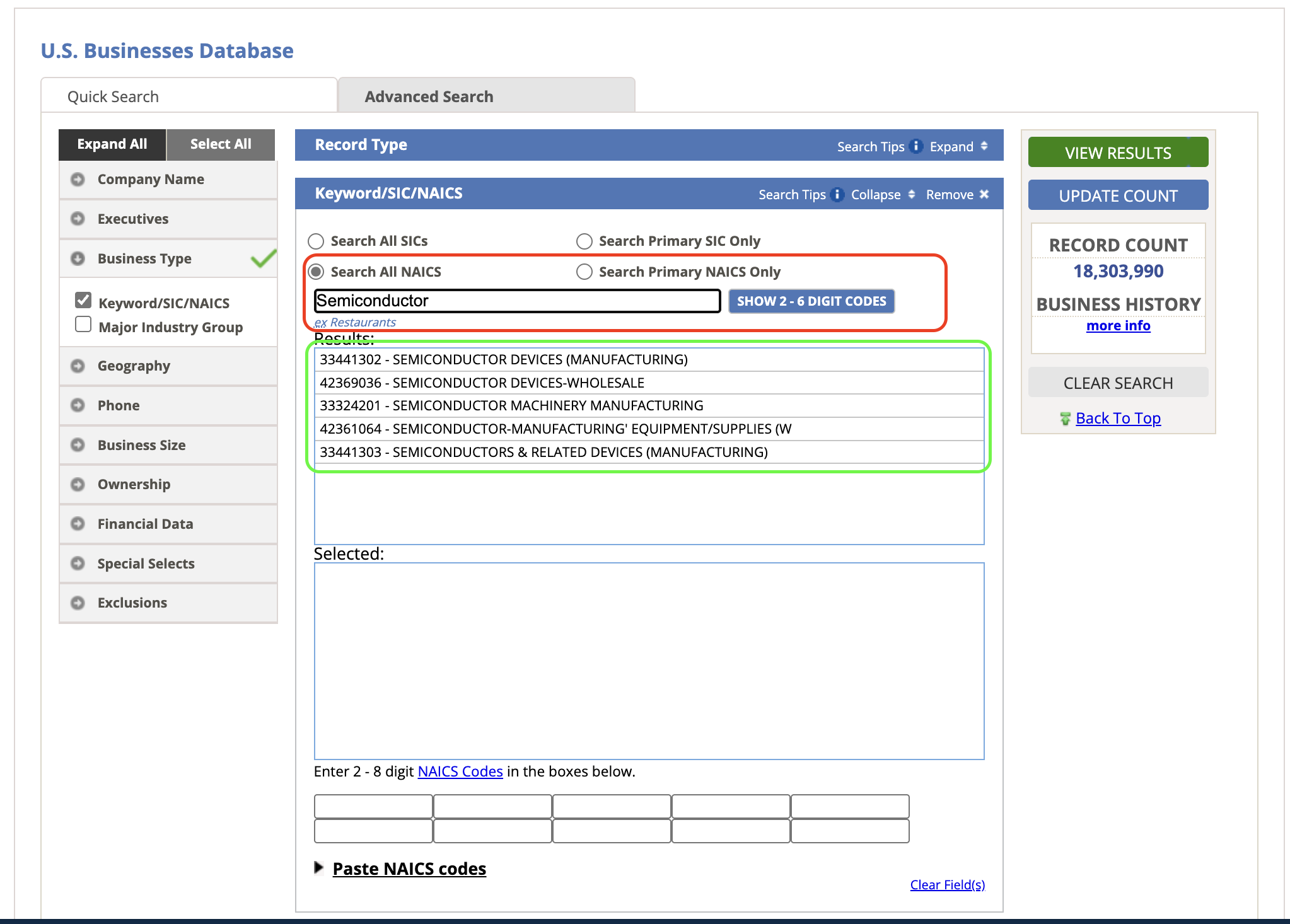
- Enter the relevant keywords or NAICS codes, select all that apply, and click Update Count.
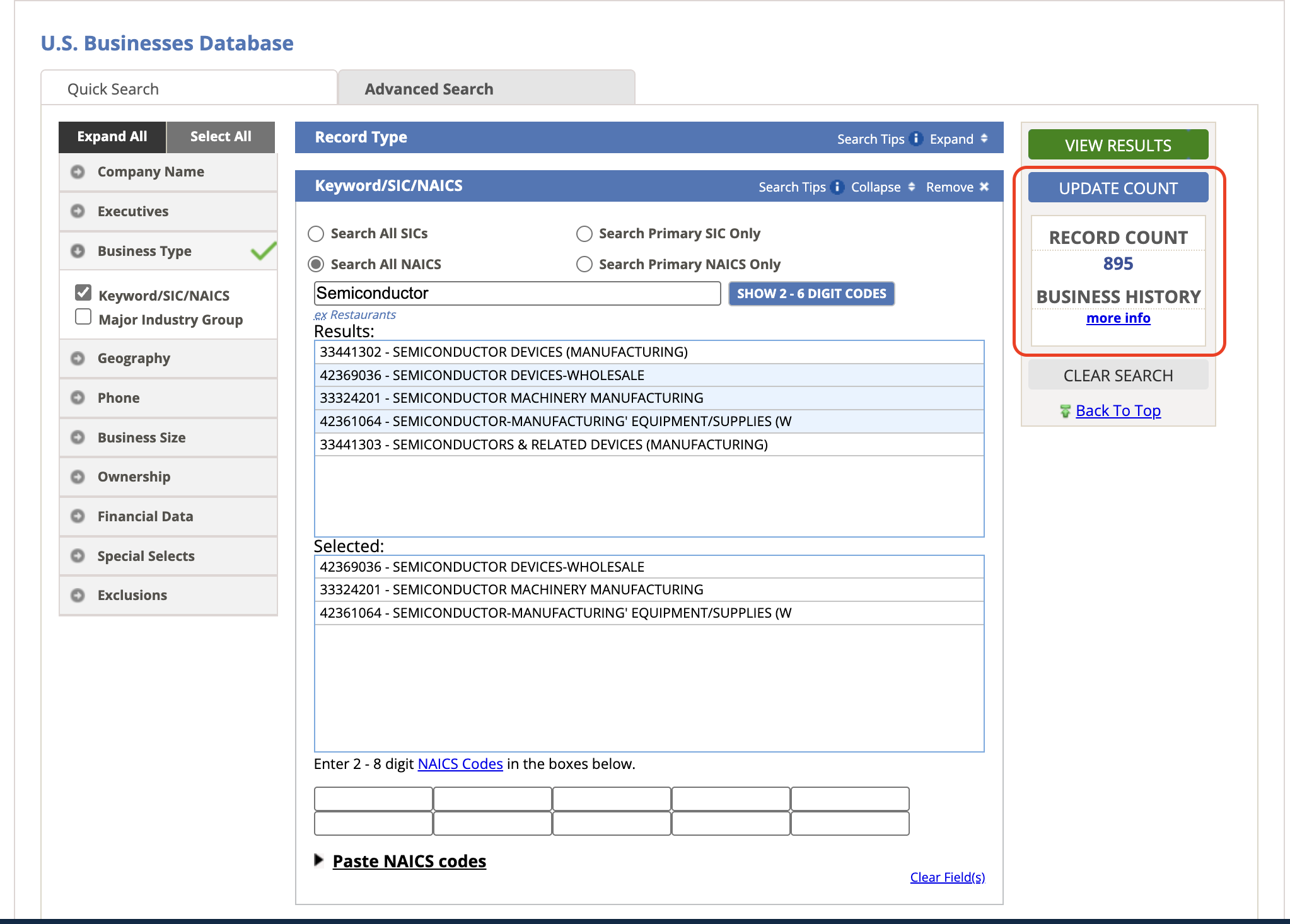
- On the View Results page, select all records (page by page) and click Download.
- In the download dialog:
- Choose Comma Delimited (CSV) format.
- Select the Detailed option in step two.
Filtering by NAICs vs Keyword
Code-only Limitations
Some firms tag themselves under a broad NAICS code but don’t actually operate in that space. For example, you might find a financial services firm classified under a manufacturing NAICS simply because of legacy or broad categorization.
Keyword Crawling
To weed out these false positives, we crawl each firm’s website:
- Fetch the homepage (and subpages) using requests/BeautifulSoup.
- Search for context signals e.g. “casting,” “foundry,” “precision,” “semiconductor,” “chip,” “electronics.”
- Drop any firms that never mention your target terms in their site content.
Core Python Pipeline
The Python pipeline is straightforward:
- Load the CSV into a Pandas DataFrame.
- Apply code-based filters (Location, Employee Size, Revenue, Expenses, Year Established, etc).
- Perform keyword crawling on filtered results.
- Compute custom ratios, if required.
- Append word counts and AI scores.
- Export the final DataFrame to Excel.
This basic flow powered our consultancy project then AI advancements made it even more powerful.
Adding AI-Driven Scoring
For AI capabilities, we need some more libraries like agno, openai, perplexity. The requirement.txt can be found at the end of the blog. To use this, you need define your thesis, what is the ideal strategic fit for your requirements and then use it as an instruction for the ai agent.
Setup the Agent
Define your acquisition thesis as instructions for the AI agent. Below is an example prompt for scoring mode (1–10 scale):
agent = Agent(
model=Perplexity(id="sonar"),
markdown=True,
instructions=[
"You are a business analyst tasked with analyzing company data.",
"For the provided company data, based on the thesis determine strategic fit:",
"Thesis: Our acquisition thesis centers on identifying U.S.-based semiconductor manufacturers ...",
"Final Output should be a single digit number between 1 and 10.",
"ONLY OUTPUT THE FINAL NUMBER, DO NOT INCLUDE ANY INTERMEDIATE STEPS OR REASONING."
],
tools=[
GoogleSearchTools(),
ReasoningTools(),
],
)Loop over your filtered list, feed the company info as a string, and append the integer score:
for i, row in sheet_one_df.iterrows():
company_info = ', '.join(f"{k}: {v}" for k, v in row.to_dict().items())
res = agent.run(company_info)
sheet_one_df.at[i, 'AI Rating (1-10)'] = int(res.content)For reasoning mode, add instructions to output a short rationale alongside the numeric score:
instructions=[
...,
"OUTPUT FORMAT:\nSTRATEGIC FIT (1-10): <digit>\nREASON: <your reason>"
]Putting It All Together
Below is a simplified, end-to-end snippet:
# 1. Load and filter
import pandas as pd
from agno.agent import Agent
# ... other imports
df = pd.read_csv('data.csv')
df_filtered = filter_df(df, codes=[...])
df_keyword = crawl_websites(df_filtered, terms=['casting', 'foundry'])
# 2. Define thesis and AI agent
# (see code above)
# 3. Run AI scoring
for i, row in df_keyword.iterrows():
info = ', '.join(f"{k}: {v}" for k, v in row.items())
score = int(agent.run(info).content)
df_keyword.at[i, 'AI Rating'] = score
# 4. Export
with pd.ExcelWriter('final_output.xlsx') as writer:
df_keyword.to_excel(writer, sheet_name='Filtered', index=False)
df.to_excel(writer, sheet_name='All', index=False)You can find the full, detailed script on GitHub.
Conclusion & Next Steps
By combining DataAxle’s exhaustive dataset with code-based filters, keyword crawling, and AI-driven scoring, you can accelerate your target identification process while maintaining precision.
Next steps:
- Integrate with your CRM or business intelligence tools.
- Implement advanced NLP filters or topic modeling.
- Build a simple GUI to make the tool accessible to non-technical colleagues.



Comments